前面介紹完基本的流程與上下文傳播,今天要準備介紹Opentelemetry Collector,但是在進入今天的主題之前,對於昨日的上下文傳播做一個小小的補充,就是有一個「Baggage」的概念,可以讓你在Trace的過程中,可以藉由上下文傳播夾帶你想要的資訊。
那補充完之後,就要進入今天的重點Opentelemetry Collector後續我會稱為「Collector」,前面的架構圖沒有把完整Collector給畫出來,所以我們再來看一下整個流程以及Collector的樣子,如下圖
那從上圖可以看到其實在Collector中的流程是:OTLP -> Receiver -> Processors -> Exporter -> Backend(e.g. Grafana、Jaeger),所以大家可以發現Collector是由三個元件「Receiver」 -> 「Processors」 -> 「Exporter」所組成。
從名字其實可以很容易的知道每個元件的功能
那什麼時候需要Collector呢?
我們先看看官方文件是怎麼說
要嘗試並開始使用 OpenTelemetry,將資料直接傳送到後端是快速獲取價值的好方法。此外,在開發或小規模環境中,無需收集器即可獲得不錯的結果。
但是,一般來說,我們建議在您的服務旁邊使用收集器,因為它允許您的服務快速卸載數據,並且收集器可以處理其他處理,例如重試、批次、加密甚至敏感資料過濾。
設定收集器也比您想像的更容易:每種語言的預設 OTLP 匯出器都假定本地收集器端點,因此如果您啟動收集器,它將自動開始接收遙測資料。
霹靂啪拉敘述了很多,大致上是在說收集、處理資料方便,非常合理也名符其實,Collector對我來說會有以下幾點重要的地方。
但是有優點也會有缺點,雖然有Collector為處理、匯出遙測資料帶來方便,可是對我來說有時候其實從可視化工具中沒有看到資料,就會開始懷疑人生,表情大概就是這樣0.0(哭啊.... 我的資料呢
其實你也不太清楚Collector到底有沒有從微服務之中接收到資料,但是回頭看看多半可能都是自己Opentelemetry 的endpoint設錯之類的。
又是老樣子分享完我自己的看法之後,不免俗還是要來看看文件怎麼說的,文件中有詳述不同三種的部署方式

優點:
缺點:
如果收集、處理發生變化,則需要更改程式碼
應用程式碼與後端高度耦合
每種語言實作的Exporter數量有限
有Collector
優點:
缺點:
可擴展性(人力和負載方面)
不靈活
建立一個 Collector Gateway
優點:
缺點:
看了文件的優缺,我只注意到一點有「上手簡單」,我二話不說就是採用了這種了XD
今日小總結
我幫忙補充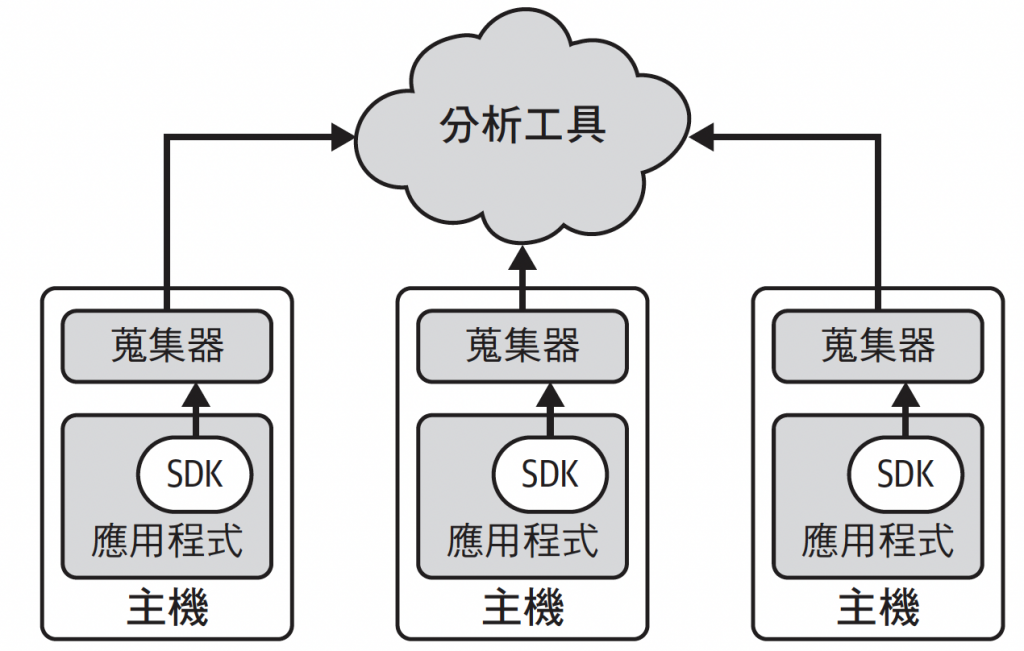
Agent 模式, 就是collector 與應用程式在同一台主機上 (想成k8s node)
又或者就是集中的一台collector
這樣的好處是什麼呢?
就是我講堂中提到的resource detector 能做在collector processor中.
程式的異動會很少, 相比於 no collector
應用程式們的exporter 設定更簡單了, 根本就是localhost 或固定的一個位置
這是團隊剛開始接觸otel collector 時應該先嘗試的系統架構
圖片出自OpenTelemetry 學習手冊 書還沒上架 XD
預計10月上架
Gateway pattern
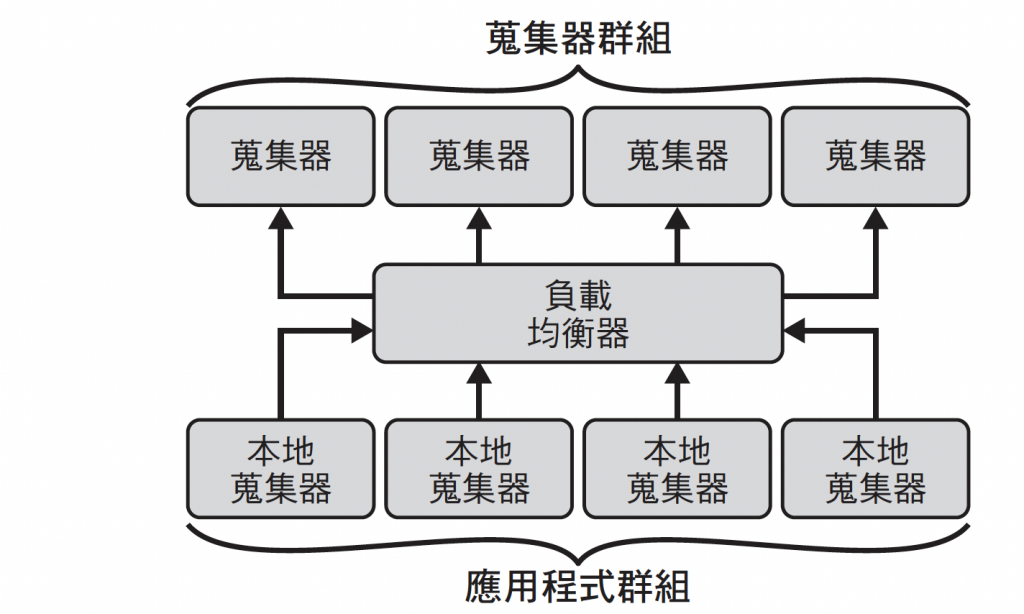
目的就是為了負載均衡來處理反壓情況
以及文章中提到的職責(功能/資源)分離
這種模式下, 本地蒐集器負責的是加法, 勁量增添上下文
而collector pool 中的collector 則是依據需求來篩選,取樣,轉換或減去上下文(減法)
圖片出自OpenTelemetry 學習手冊 書還沒上架 XD
預計10月上架



 iThome鐵人賽
iThome鐵人賽